What is it?
ClusterCockpit is a monitoring framework for job-specific performance and power monitoring on distributed HPC clusters. The focus is put on simple installation and maintenance, high security and intuitive usage. ClusterCockpit provides a modern web interface which provides:
- HPC Users an overview about their running and past batch jobs with access to various metrics including hardware performance counter data. Jobs can be sorted, filtered, and tagged.
- Support staff an easy access to all job data on multiple clusters. Jobs and users can be sorted and filtered using a very flexible interface. Job and user data can be aggregated using a customisable statistical analysis. There is a status view providing an overview for all clusters.
- Administrators single file deployment for the ClusterCockpit web backend. A Systemd setup for easy control. RPM and DEB packages for the node agent. For authentication local accounts, LDAP, and JWT tokens are supported. There exists an extensive REST API to integrate into a existing monitoring and batch job scheduler infrastructure.
ClusterCockpit is used in production at several Tier-2 HPC computing centers, you can find a list here. It should work for small to medium HPC clusters.
Warning
Because ClusterCockpit performs no data reduction for jobs with many nodes and a long duration there are currently limits to the job sizes that can be viewed. This will be resolved in a future release.How does it work?
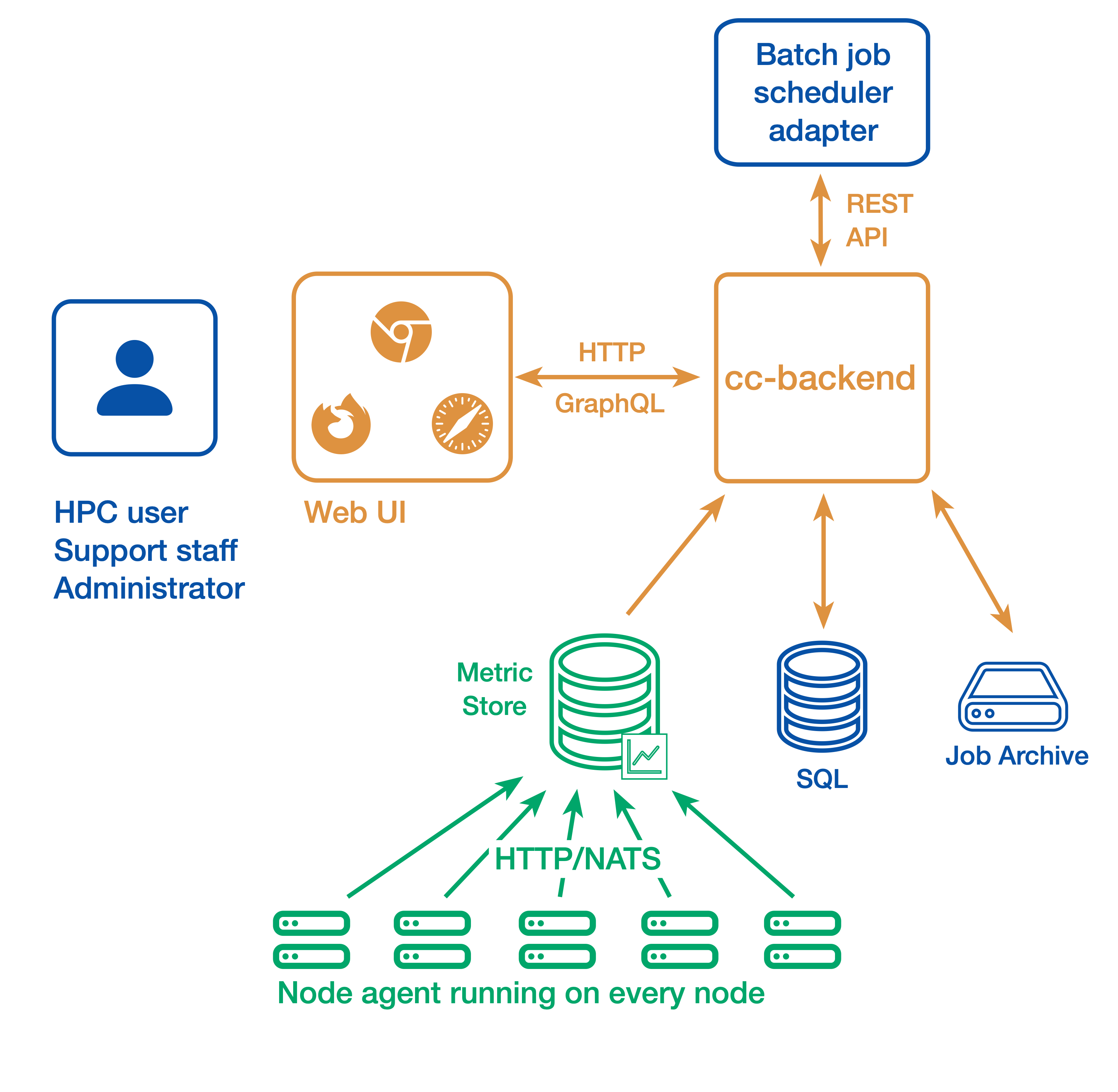
ClusterCockpit consists of
- the web user interface and API backend cc-backend
- the node agent cc-metric-collector
- and the in-memory metric cache cc-metric-store
All components can also be used individually.
Node metrics are collected continuously and sent to the metrics store at fixed intervals. Job details are provided by an external adapter for the batch job scheduler and sent to cc-backend via a REST API. For running jobs, cc-backend queries the metrics store to collect all required time series data. Once a job is finished, it is persisted to a JSON file-based job archive that contains all job metadata and metrics data. Finished jobs are loaded from the job archive. The metrics store uses cyclic buffers and stores data only for a limited period of time.
Where should I go next?
Give your users next steps from the Overview. For example:
- Getting Started: Get started with ClusterCockpit
- User guide: A user guide for the ClusterCockpit web interface